Day 76 - 모니터링 환경 재시도
모니터링 환경 구성을 다시 시도했다. 메모리 초과 문제를 방지하기 위해 기존에 올려두었던 모든 리소스를 삭제하고, 모니터링 환경에 필요한 리소스만 최소한을 구성했다.
이 과정에서 문제를 발견할 수 있었다.
문제
peration error EC2: CreateVolume, get identity: get credentials: request canceled, context canceled
CSI Driver Controller 파드에서 해당 에러 발
원인
- CSI Driver Controller 파드가 EC2 볼륨 생성 권한을 제대로 획득하지 못함
- IAM Role과 Policy는 정상적으로 생성되어 있었고, Pod에도 ServiceAccount로 잘 매핑되어 있었음
미해결
- 권한과 설정을 여러 번 확인했지만 끝내 해결하지 못함
- 내부 네트워크 문제까지 겹쳐 결국 기존 Cluster를 삭제하고 새로 생성하기로 결정
Day 77 - Cluster 재생성
어제의 문제를 결국 해결하지 못하고 Cluster를 다시 만들었다.
Terraform 주석 처리로 Cluster와 관련된 모든 리소스를 삭제하고, 다시 주석을 풀어 생성하는데만 2시간이 걸린 것 같다.
이번에는 네트워크 문제 없이 Pod들이 정상적으로 DynamoDB나 S3에 접속하여 API 호출에 문제가 없었다.
그렇게 정상적으로 동작하는 것을 확인하고 나니 마음이 편해졌다. 그리고 조금 미뤄왔던 namespace 구분을 하기 위해 다시 삭제했다.🥲 데이터 조회용 서비스와 데이터 수집용 서비스를 나누기 위해 news-api와 news-collector namespace를 생성하고 기존 리소스들을 할당해주었다. 이 과정은 kubectl apply -f news-service.yaml 을 실행해놓고 저녁 먹고 강아지랑 산책까지 하고 왔더니 Route53에 고정 도메인도 생성되어 있었고 정상적으로 Pod들이 동작하는 걸 확인할 수 있었다.
이번 Cluster 재생성 과정에서 내가 깨달은 건 생각보다 Kubernetes 내부에서 리소스 변경 감지가 오래 걸린다는 것이었다. 물론 어떤 리소스냐에 따라 다른 것 같긴 하지만 Ingress 부분은 확실히 오래 기다려야 했다. 정상 작동되는지 빨리 확인하려는 마음에 조금 조급해서 rollout이나 삭제하고 다시 올려볼까를 고민하다가 조금만 더 기다려보니 정상적으로 동작했다! 기다림이 필요한 작업이었던 것이다.

Day 78 - 고가용성 확보
HPA 구성
고가용성을 구성하기 위해 news-api 서비스를 위한 HPA와 PB를 생성했다.
HPA는 Horizontal Pod Autoscaler로 리소스 사용량이 기준치를 넘었을 때 Pod를 자동으로 늘려주는 역할을 한다. 덕분에 서비스가 갑자기 많은 요청을 받더라도 안정적으로 대응할 수 있게 된다.
PB는 Pod Disruption Budget으로 최소 몇 개의 Pod가 반드시 살아있어야 하는지를 정해주는 정책인데, 이를 통해 클러스터 운영 과정에서 불필요하게 Pod가 모두 사라지는 상황을 막을 수 있다. 예를 들어 3개의 노드에 Pod가 각각 1개씩 배치되어 있을 때, 노드 2개를 삭제하려는 시도가 있더라도 PB에 최소 2개의 Pod를 유지하라는 조건을 걸어두면 일부는 지워지더라도 나머지는 반드시 남게 된다.
HPA가 제대로 동작하기 위해서는 리소스 사용량을 감시할 수 있는 Metrics Server도 필요해서 함께 설치했다.

Karpenter 설치
노드의 Auto Scaling을 위해 Karpenter를 설치했다.
쿠버네티스 초창기에는 Cluster Autoscaler(CA)라는 오픈소스를 사용했다고 한다. 아무래도 오래되었다보니 기본적으로 여러 클라우드 벤더와 호환이 가능하다는 장점이 있지만 새로운 노드를 프로비저닝하기 위해 ASG를 거쳐야 하다보니 상대적으로 좀 느리고 노드 그룹은 하나의 노드 타입과 크기를 정할 수 있다보니 리소스를 낭비한다는 단점이 있다.
Karpenter는 AWS가 개발한 오픈소스이며 Kubernetes-Native로 동작한다. Pending Pod를 감지해서 구동할 수 있는 최적화된 노드를 선택해 프로비저닝해준다. CA보다 빠르게 프로비저닝이 트리거되고, CRD를 통해 다양한 노드 타입, 크기 후보군을 정할 수 있어 최적의 노드를 자동으로 선택해 프로비저닝해준다는 장점이 있다. 무엇보다 최근에는 안정화된 버전도 많이 나왔고, AWS에서도 권장하는 방식이라 고민 없이 Karpenter를 도입했다.
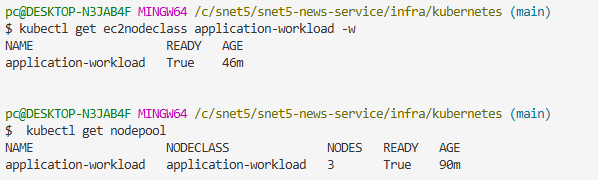
Day 79 - Karpenter 에러 고치기 & 모니터링 환경
Karpenter 에러 고치기
1. NodeClass 설정 문제
문제
- 증상: NodeClaim이 생성되지만 NodeClassReady=False 상태 지속
- 오류 메시지: failed to discover any AMIs for alias (alias=al2023@2023.4.20240401.1)
원인
- 존재하지 않는 AMI 별칭 사용
해결
- 올바른 AMI 별칭으로 수정: al2023@latest
AL2(Amazon Linux 2)의 경우 2025년 11월에 서비스 종료 예정이라 AL2023 사용
2. Bootstrap 스크립트 호환성 문제
문제
- 증상: EC2 인스턴스는 실행되지만 EKS 클러스터에 조인 실패
- 오류 메시지: bootstrap.sh has been removed from AL2023-based EKS AMIs
원인
- Amazon Linux 2023에서는 bootstrap.sh 대신 nodeadm 사용
- 기존 AL2 방식의 UserData 스크립트가 AL2023에서 작동하지 않음
해결
- UserData를 완전히 제거하여 Karpenter가 자동으로 nodeadm 설정 생성하도록 변경
3. IAM 권한 문제
문제
- 증상: kubelet이 Unauthorized 오류로 EKS API 서버 접근 실패
- 오류 메시지: Unable to register node with API server" err="Unauthorized"
원인
- aws-auth ConfigMap에 Karpenter 노드 IAM 역할이 등록되지 않음
- EKS 클러스터가 Karpenter 노드를 신뢰하지 않음
해결
aws-auth ConfigMap에 Karpenter 노드 역할 추가
4. DNS 해석 실패 문제
문제
- 증상: Pod에서 외부 DNS 해석 실패
- 오류 메시지: Could not connect to the endpoint URL: "https://sts.ap-northeast-2.amazonaws.com/"
- 테스트 결과: curl: (28) Resolving timed out after 5000 milliseconds
원인
- Karpenter 노드에서 CoreDNS Pod로의 UDP 53 포트 통신이 보안그룹에서 차단됨
- CoreDNS는 관리형 노드에만 배포되어 있었고, Karpenter 노드에서 DNS 쿼리가 실패
해결
Terraform 보안그룹에 DNS 포트 추가
5. Karpenter Pod 안정성 문제
문제
- 증상: Karpenter Pod가 CrashLoopBackOff 상태로 재시작 반복
- 원인: Pod Anti-Affinity 규칙으로 인해 동일 노드에 여러 Pod 배치 불가
해결
- Karpenter deployment replicas를 1로 조정하여 안정성 확보
CloudWatch Agent 설치
메트릭 수집과 모니터링 환경을 구성하기 위해 CloudWatch를 사용하기로 했다.
EKS Addon 중에 CloudWatch Observability를 설치하면 CloudWatch Agent와 FluentBit가 같이 설치되는데, 이를 통해 메트릭을 수집하고 모니터링 환경을 구성할 수 있다.
설치와 간단한 구성을 마치고 메트릭이 수집되는 걸 기다렸다. 한 10분 넘게 기다린 후에 명령어로 메트릭 수집 현황을 확인해봤는데 아주 대표적인 값들도 수집이 안되고 있어서 당황했다. 처음엔 권한이 부족해서 생긴 문제였고, 두번째는 내가 메트릭 수집 확인하는 명령어를 공홈에서 그대로 가져와서 사용해서 확인이 안된 문제였다....😅 빨리 끝내고 싶은 마음에 좀 많이 서둘렀나보다 ㅠㅠ 다행히 권한과 명령어를 바로잡고 나니 메트릭 수집이 잘 되었고, CloudWatch Container Insights 대시보드도 정상적으로 구성되었다.

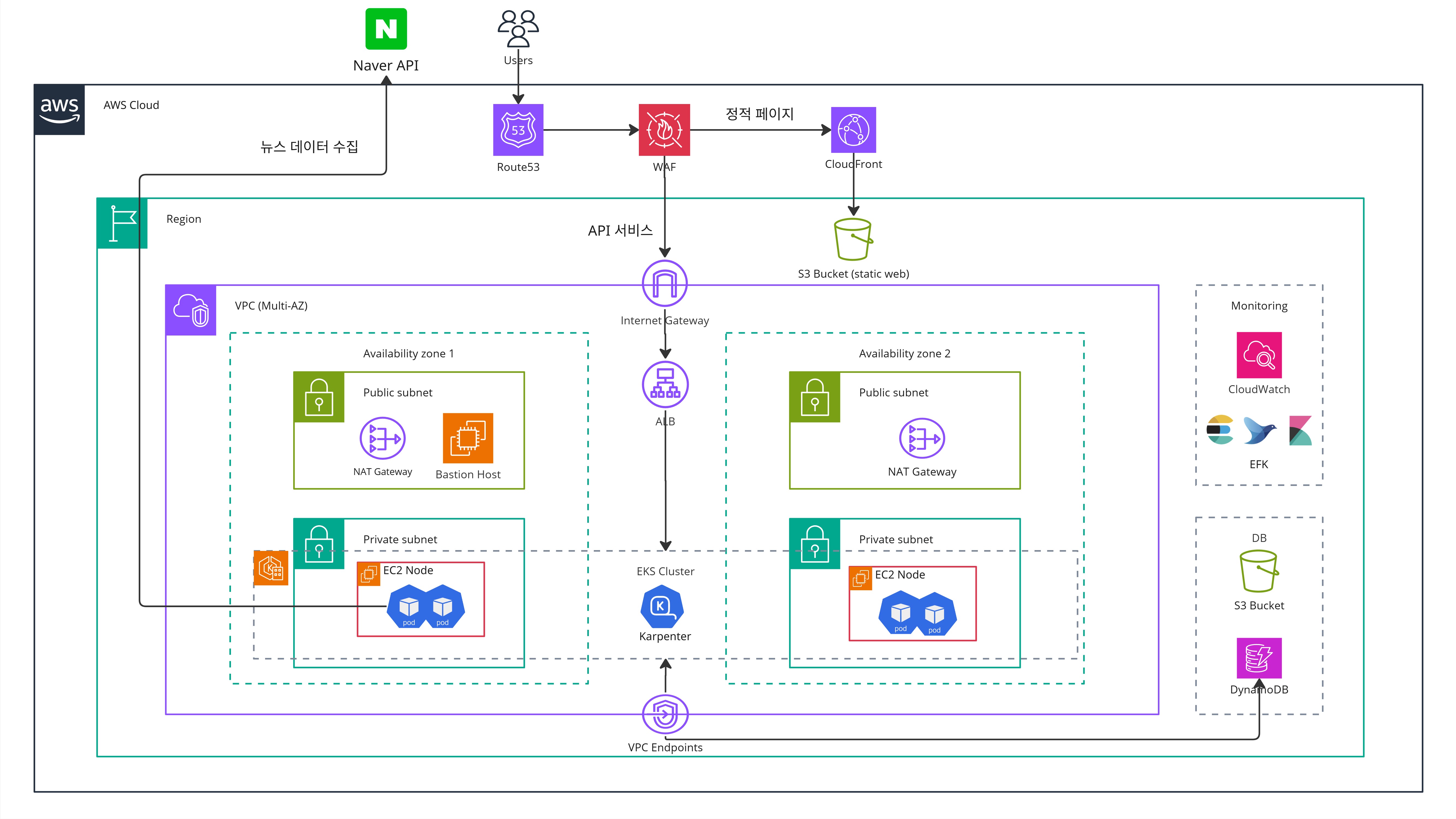
아키텍처 다이어그램 수정
사실 크게 바뀔 부분은 없었지만, EKS 내부 구성을 조금 더 반영해야 해서 수정 작업이 필요했다. 프로젝트 일정이 바쁘다 보니 멘토링 전날 밤늦게까지 급히 작업을 했고, 그 덕분에 자격증 공부는 거의 못 했다🥲 그래도 다이어그램이 정리되니 마음은 한결 놓였다.


Day 80 - 멘토링 & 모의면접
멘토링 피드백
CI/CD 전략
도입 툴:
- ArgoCD: GitOps 기반 배포 관리에 활용
- Github Actions: 익숙하고 빠르게 파이프라인 구성 가능
추가 고려사항
- 다른 팀처럼 시연 영상 준비 (검증 & 공유 목적)
IaC (Terraform) 관리 범위
관리 범위:
- 일반적으로 네트워크 리소스 + EKS 클러스터 생성까지만 Terraform으로 관리 (멘토님 의견)
- 그 외 어플리케이션 레벨 리소스는 Helm, ArgoCD 등으로 분리 관리 가능
문서화 & 자동화:
- Terraform 내에서 Markdown 활용 → 코드 변경 시 문서 자동 반영
- 문서/코드 동기화 관리로 유지보수성 향상
모의면접
지난번에 받았던 피드백을 반영해 프로젝트별 설명을 보강했고, 자유 양식으로 포트폴리오를 작성해 준비했다. 취업용 사진도 새로 찍어서 첨부했는데, SAA 자격증을 땄다면 더 좋았을 텐데라는 아쉬움이 남았다. 프로젝트 과정에서 예상치 못한 에러가 자주 발생하다 보니, 교육이 끝나는 오후 6시 이후에도 문제를 파악하고 해결하는 데 시간을 거의 다 쓰게 되었고, 그만큼 자격증 공부에 투자할 시간이 부족했다.
아쉽게도 이번에 지원한 에스넷 그룹의 채용 공고에는 클라우드나 개발자 직무가 없어서, 내가 진행한 프로젝트 내용을 크게 어필할 기회가 없었던 것 같다. 관련 직무 공고가 하루빨리 올라오기를 바랄 수밖에 없다. 면접에서 간단한 기술 질문도 받았는데, 대답을 하다 보니 조금 두서 없이 말하게 된 것 같아 아쉬움이 남았다. 확실히 머릿속으로 공부한 내용과 실제로 말로 풀어내는 것은 차이가 크다는 걸 다시 한번 느꼈다. 이제는 클라우드 관련 기술 면접에 대해서도 본격적으로 대비해야겠다고 다짐하게 되었다. .
✍️ 주간 회고
이번 주는 문제 상황이 생겨도 빠르게 원인을 파악하고 해결해나가면서, 계획했던 일들을 대부분 해낼 수 있었다는 점에서 나름 성과가 있었다. 다만 Prometheus와 Grafana로 모니터링 환경을 끝내 구축하지 못한 건 정말 아쉽게 남는다. 이미 한 차례 실패를 경험했던 터라 프로젝트가 얼마 남지 않은 지금, 다시 도전하기에는 부담이 컸다. 그래서 안정적인 진행을 위해 무리한 시도는 하지 않기로 했다.
요구사항은 어느 정도 충족해 나가고 있지만 아직 해야 할 일들이 많이 남아 있다. 특히 EFK 스택 구축과 CI/CD 파이프라인 정리, 발표 준비까지 고려하면 평일 기준 7일밖에 남지 않은 일정이 상당히 촉박하게 느껴진다. 게다가 다음 주 일요일에는 네트워크 관리사 2급 실기 시험까지 예정되어 있어 프로젝트와 자격증 시험, 그리고 하반기 채용 준비가 한꺼번에 맞물려 하루 종일 책상 앞을 지켜야 하는 상황이다. 체력적으로도 정신적으로도 쉽지 않지만, 남은 며칠만 더 집중해서 버티고 하루 이틀 정도는 꼭 쉬어야겠다고 마음먹었다. 이후에는 다시 SAA와 CKA 자격증 준비에 집중해 나갈 계획이다.
'TIL' 카테고리의 다른 글
| [에스넷시스템 부트캠프] TIL Day 86~88 - 프로젝트 발표 및 최우수상 수상 (0) | 2025.09.23 |
|---|---|
| [에스넷시스템 부트캠프] TIL Day 81~85 - 프로젝트 8주차 (0) | 2025.09.21 |
| [에스넷시스템 부트캠프] TIL Day 72~75 - 프로젝트 6주차 (0) | 2025.09.04 |
| [에스넷시스템 부트캠프] TIL Day 67~71 - 프로젝트 5주차 (3) | 2025.08.30 |
| [에스넷시스템 부트캠프] TIL Day 62~66 - 프로젝트 4주차 (0) | 2025.08.23 |